VibeVoice: The Hour-Long Storyteller

⚡ TLDR
- What it solves: Speech models that lose track of who is talking after 30 seconds - VibeVoice processes a full hour in a single pass.
- Why it matters: Chunked models stitch audio and the seams show: speakers swap accents, context resets, and long meetings become gibberish.
- Best for: Developers building long-form podcast generation, academic lecture transcription, or multi-speaker dialogue synthesis.
- Main differentiator: A continuous 7.5 Hz tokenizer keeps the full audio context in one pass instead of slicing and praying the joins hold.
- Usecase example: Transcribing a 45-minute technical stand-up with six speakers and custom hotwords without a single diarization reset.
I recently watched a ‘synthetic podcast’ generated by a popular AI agent. For the first five minutes, it was brilliant. Two distinct voices, sharp banter, great timing. Then, around the seven-minute mark, something shifted. The host started answering their own questions. The guest adopted the host’s accent. By the ten-minute mark, it was just one wandering monologue.
The AI didn’t run out of intelligence; it ran out of breath.
Most speech models today are like sprinters forced into a marathon. They slice audio into 30-second chunks, process them in isolation, and pray the stitches don’t show. But the stitches always show. You lose the ‘Who,’ you lose the ‘When,’ and eventually, you lose the ‘What.‘
The Elephant in the Room
VibeVoice, a recent release from Microsoft Research, is what happens when you build for the marathon from day one. It is a family of speech models - Automatic Speech Recognition (ASR), Text-to-Speech (TTS), and Real-time Streaming - that treats duration as a feature, not a constraint.
Physically, VibeVoice is a collection of weights and a ‘next-token diffusion’ framework. But mentally, it is an elephant with a perfect memory.
While conventional models are frantically looking at their map every few yards, VibeVoice has already memorized the route. Its core innovation is a continuous speech tokenizer that operates at an ultra-low 7.5 Hz. It preserves the audio fidelity while keeping the computational cost low enough to process an hour of audio in a single pass.
What’s Inside the Box
The family is split into three main tools, each solving a different side of the “long-form” problem:
- VibeVoice-ASR (7B): Handles up to 60 minutes of audio. It doesn’t just transcribe; it diarizes. It knows who said what and when for the entire hour.
- VibeVoice-TTS (1.5B): Synthesizes up to 90 minutes of multi-speaker dialogue. (Note: Microsoft restricted the full weights due to deepfake concerns, but the 0.5B realtime version is open).
- VibeVoice-Realtime (0.5B): A lightweight streaming version for sub-300ms latency.
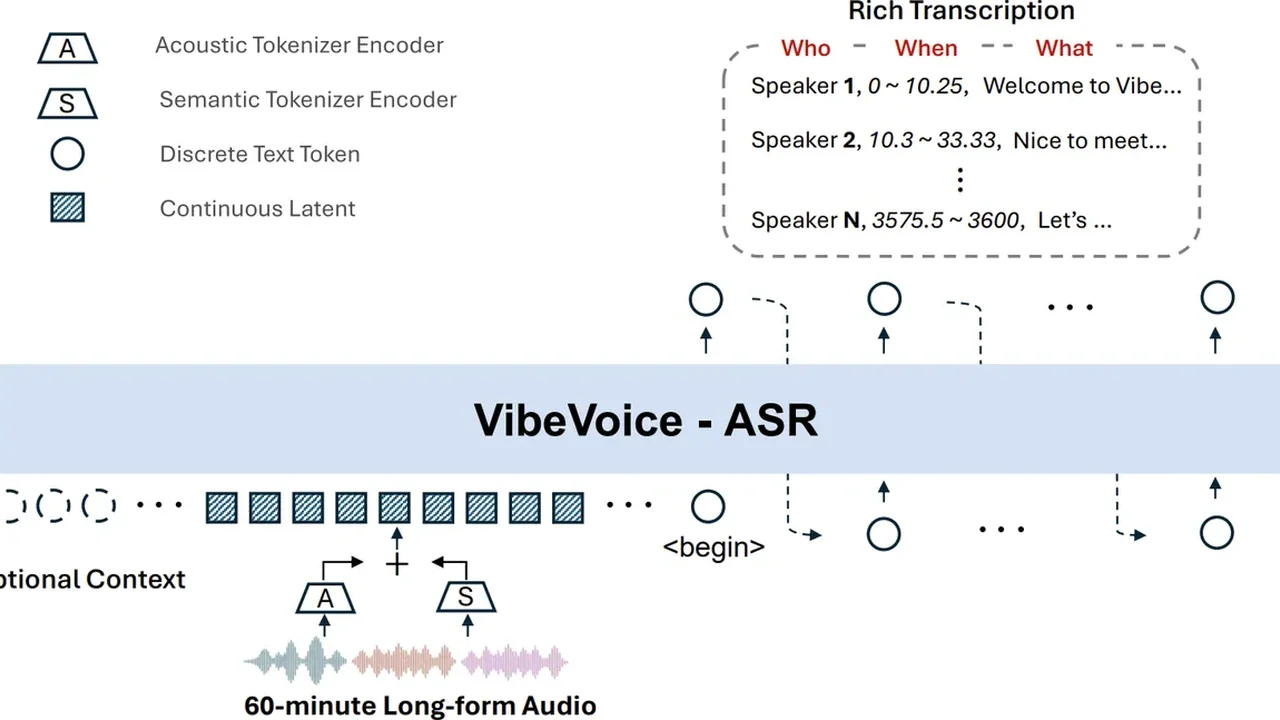
The Single-Pass Difference
The difference between “chunking” and “single-pass” is the difference between reading a book one page at a time with a blindfold on between pages, vs. keeping the book open on the table.
| Feature | The Old Way (Chunking) | VibeVoice (Single-Pass) |
|---|---|---|
| Speaker Diarization | Resets every 30s; gets confused | Consistent for 60+ minutes |
| Context | Lost at the boundaries | Preserved across the hour |
| Artifacts | Audible clicks or tonal shifts | Smooth, continuous flow |
| Hotwords | Hard to inject globally | Supported for technical terms |
If you’ve ever tried to transcribe a technical meeting where people mention “Kubernetes” or specific internal project names, you know they usually come out as gibberish. VibeVoice lets you feed in “Hotwords” to guide the recognition.
Performance that Sticks
The technical metrics show it isn’t just a marketing claim. The Diarization Error Rate (DER) stays remarkably low even in complex multi-lingual scenarios.
Real-World Grounding
Think about the use cases that usually break today:
- Long-form Podcasts: Converting a 45-minute script with 4 speakers without everyone sounding like the same person by the end.
- Academic Lectures: 60 minutes of dense technical talk where specific “hotwords” matter.
- Interactive Agents: Systems that need to listen for an hour and then respond with perfect awareness of who said what.
The Honest Tradeoff
Every elephant eats a lot.
- VRAM: The ASR-7B model isn’t going to run on your average laptop. You need a decent GPU (A100/H100 preferred for full speed).
- TTS Removal: The most “magical” part - the long-form 1.5B TTS - was pulled from the public repo. Microsoft’s safety team deemed the risk of impersonation too high. You can still use the 0.5B realtime model, but the 90-minute multi-speaker holy grail is currently behind the gates.
The Turn
We are moving away from “smart enough for a minute” to “reliable for an hour.” VibeVoice isn’t trying to be the most expressive actor or the fastest whisperer. It’s trying to be the one that doesn’t lose the thread.
In a world full of goldfishes, sometimes you just need an elephant.

Hoang Yell
A software developer and technical storyteller. I spend my time exploring the most interesting open-source repositories on GitHub and presenting them as accessible stories for everyone.


