VibeVoice: Khi AI kể chuyện suốt một giờ

⚡ TLDR
- Giải quyết vấn đề: Các mô hình giọng nói cắt đoạn 30 giây rồi khâu lại - VibeVoice xử lý nguyên tiếng đồng hồ trong một lần chạy duy nhất.
- Tại sao quan trọng: Khi khâu nối, người nói đổi giọng, mốc thời gian biến mất, cuộc họp dài trở thành mớ bòng bong.
- Phù hợp với: Ai đang xây dựng podcast tổng hợp dài, chép lại bài giảng học thuật, hay tạo hội thoại nhiều người nói.
- Điểm khác biệt: Bộ mã hóa liên tục 7.5 Hz giữ nguyên toàn bộ ngữ cảnh âm thanh, không cắt không khâu.
- Ví dụ thực tế: Transcribe một buổi stand-up 45 phút với sáu người, có hotwords kỹ thuật, không bị diarization reset lần nào.
Hôm trước tôi nằm nghe một podcast ‘giả lập’ do AI tạo ra. Năm phút đầu thì ổn lắm, hai giọng nam nữ đối đáp như thật, thỉnh thoảng còn chêm mấy câu đùa duyên dáng. Nhưng đến phút thứ bảy thì ‘bà host’ bắt đầu trả lời luôn phần của khách mời. Phút thứ mười, ông khách bỗng dưng đổi giọng y hệt bà host.
Cuối cùng, nó biến thành một màn độc thoại kéo dài trong vô vọng. Con AI không thiếu thông minh, nó chỉ… hụt hơi.
Đa số các mô hình giọng nói hiện nay giống như những vận động viên chạy nước rút bị ép đi thi marathon. Chúng phải cắt nhỏ file âm thanh ra từng đoạn 30 giây, xử lý riêng lẻ rồi khâu lại. Mà đã là đồ khâu thì thế nào cũng lộ vết. Bạn mất dấu người nói, mất mốc thời gian, và cuối cùng là mất luôn cả nội dung.
Chuyện con voi có trí nhớ tốt
VibeVoice, một bộ mô hình vừa được Microsoft Research công bố, là câu trả lời cho việc ‘chạy bền’ ngay từ lúc khai sinh. Nó là một tập hợp các mô hình từ nhận diện (ASR), tổng hợp (TTS) đến truyền phát thời gian thực (Real-time).
Về mặt vật lý, VibeVoice là một đống file weights và cái framework ‘next-token diffusion’ phức tạp. Nhưng về mặt tinh thần, nó giống như một con voi với trí nhớ hoàn hảo.
Trong khi các mô hình thông thường cứ chạy được vài mét lại phải lôi bản đồ ra xem mình đang ở đâu, thì VibeVoice đã thuộc lòng cả lộ trình. Cốt lõi của nó nằm ở bộ mã hóa âm thanh (tokenizer) hoạt động ở tần số cực thấp 7.5 Hz. Nó vừa đủ để giữ độ nét của giọng nói, vừa đủ nhẹ để xử lý cả tiếng đồng hồ âm thanh trong đúng một lần chạy (single-pass).
Có gì trong ‘hộp’ của Microsoft?
Bộ sưu tập này chia làm ba nhánh chính:
- VibeVoice-ASR (7B): Nhận diện âm thanh lên tới 60 phút. Nó không chỉ chép lại lời, nó còn biết ‘phân vai’. Ai nói cái gì, lúc nào, xuyên suốt cả tiếng đồng hồ. Đặc biệt, nó hỗ trợ tiếng Việt cực tốt (sai số diarization chỉ 0.16% trong thử nghiệm).
- VibeVoice-TTS (1.5B): Tổng hợp giọng nói cho hội thoại nhiều người lên tới 90 phút. (Tiếc là Microsoft đã rút file weights bản này vì sợ bị lạm dụng làm deepfake, nhưng bản realtime 0.5B vẫn còn).
- VibeVoice-Realtime (0.5B): Bản siêu nhẹ, độ trễ chỉ dưới 300ms, chuyên dùng để stream.
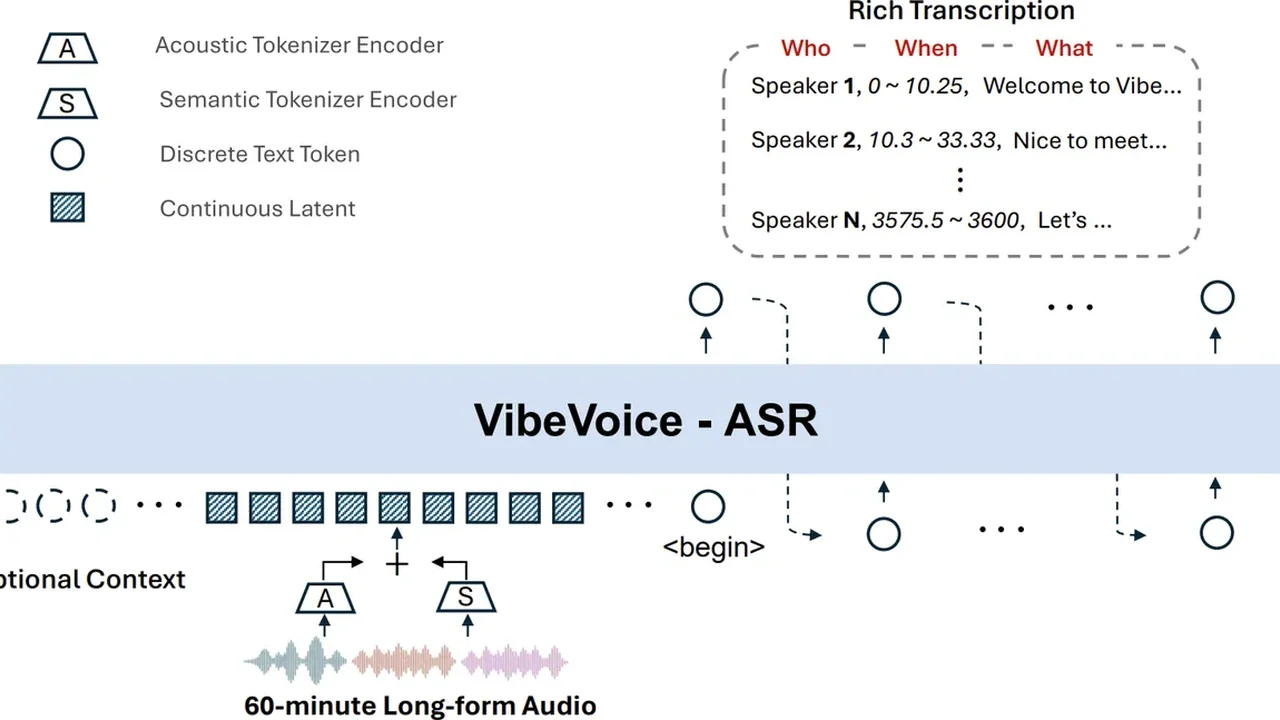
Khác biệt của việc ‘không cắt đoạn’
Sự khác biệt giữa việc ‘cắt đoạn’ (chunking) và ‘chạy một lèo’ (single-pass) giống như việc bạn đọc một cuốn sách mà cứ mỗi trang lại bị bịt mắt một lần, so với việc trải cả cuốn sách ra trên mặt bàn.
| Tính năng | Cách cũ (Cắt đoạn) | VibeVoice (Chạy một lèo) |
|---|---|---|
| Phân vai người nói | Reset mỗi 30 giây; dễ nhầm lẫn | Đồng nhất suốt 60+ phút |
| Bối cảnh (Context) | Mất dấu ở các điểm nối | Giữ nguyên mạch cảm xúc |
| Từ khóa (Hotwords) | Khó chèn vào đồng bộ | Hỗ trợ từ chuyên môn cực tốt |
Nếu bạn từng thử dùng AI để ghi biên bản họp kỹ thuật, nơi người ta cứ nh nhắc đến mấy từ như “Kubernetes” hay tên dự án nội bộ, bạn sẽ thấy nó thường biến thành chữ gì đó lăng nhăng. VibeVoice cho phép bạn nạp trước “Hotwords” để dẫn đường cho nó.
Con số không biết nói dối
Dữ liệu thực tế cho thấy đây không phải là lời hứa suông. Tỷ lệ sai lệch khi phân vai (DER) của VibeVoice ở mức rất thấp, ngay cả trong môi trường đa ngôn ngữ phức tạp.
Đánh đổi thực tế
Con voi nào cũng ăn rất nhiều.
- VRAM: Bản ASR-7B không dành cho laptop văn phòng. Bạn cần một GPU ra trò (A100/H100 là tốt nhất) để nó chạy mượt.
- Weights bị rút: Cái phần ‘màu nhiệm’ nhất - bản TTS 1.5B xử lý 90 phút - đã bị gỡ khỏi public repo. Đội ngũ an toàn của Microsoft nhận thấy rủi ro giả mạo giọng nói quá cao. Bạn vẫn dùng được bản realtime 0.5B, nhưng ‘chén thánh’ TTS 90 phút thì hiện tại vẫn đang bị khóa kín.
Kết
Chúng ta đang bước ra khỏi kỷ nguyên “thông minh trong một phút” để tiến tới “tin cậy trong một giờ”. VibeVoice không cố gắng trở thành diễn viên lồng tiếng hay nhất hay người nghe lén nhanh nhất. Nó chỉ cố gắng là người không bao giờ mất dấu câu chuyện.
Giữa một thế giới toàn cá vàng, thỉnh thoảng ta lại cần một con voi.

Hoang Yell
Một nhà phát triển phần mềm và là người kể chuyện kỹ thuật. Tôi dành thời gian để khám phá những repository mã nguồn mở thú vị nhất trên GitHub và trình bày chúng dưới dạng những câu chuyện dễ hiểu cho mọi người.


